

Hi!
Intro [CV]
I am currently a Postdoctoral Research Fellow at MMLab@NTU, Singapore, working with Prof. Ziwei Liu. Prior to this, I got my Ph.D. at GAP Lab, advised by Prof. Xiaoguang Han, at the Chinese University of Hong Kong (Shenzhen) . I completed my M.Sc. at the University of California, Irvine and my B.Eng. at Xidian University. I am fortunate to have worked at CVMI Lab under the guidance of Prof. Xiaojuan Qi and at SIAT-MMLab under the supervision of Prof. Yu Qiao .
My research is centered around developing intelligent algorithms and creating diverse data to comprehend, model, represent, and interact with the 3D physical world. Currently, I am keenly interested in Embodied AI.News
- [11/2025] I was awarded Presidential Award for Outstanding Doctoral Students of CUHKSZ and was selected as the representative to deliever a speech at the graduation ceremony.
- [09/2025] I was recognized as one of the ICCV2025 Outstanding Reviewers (2.7%)!
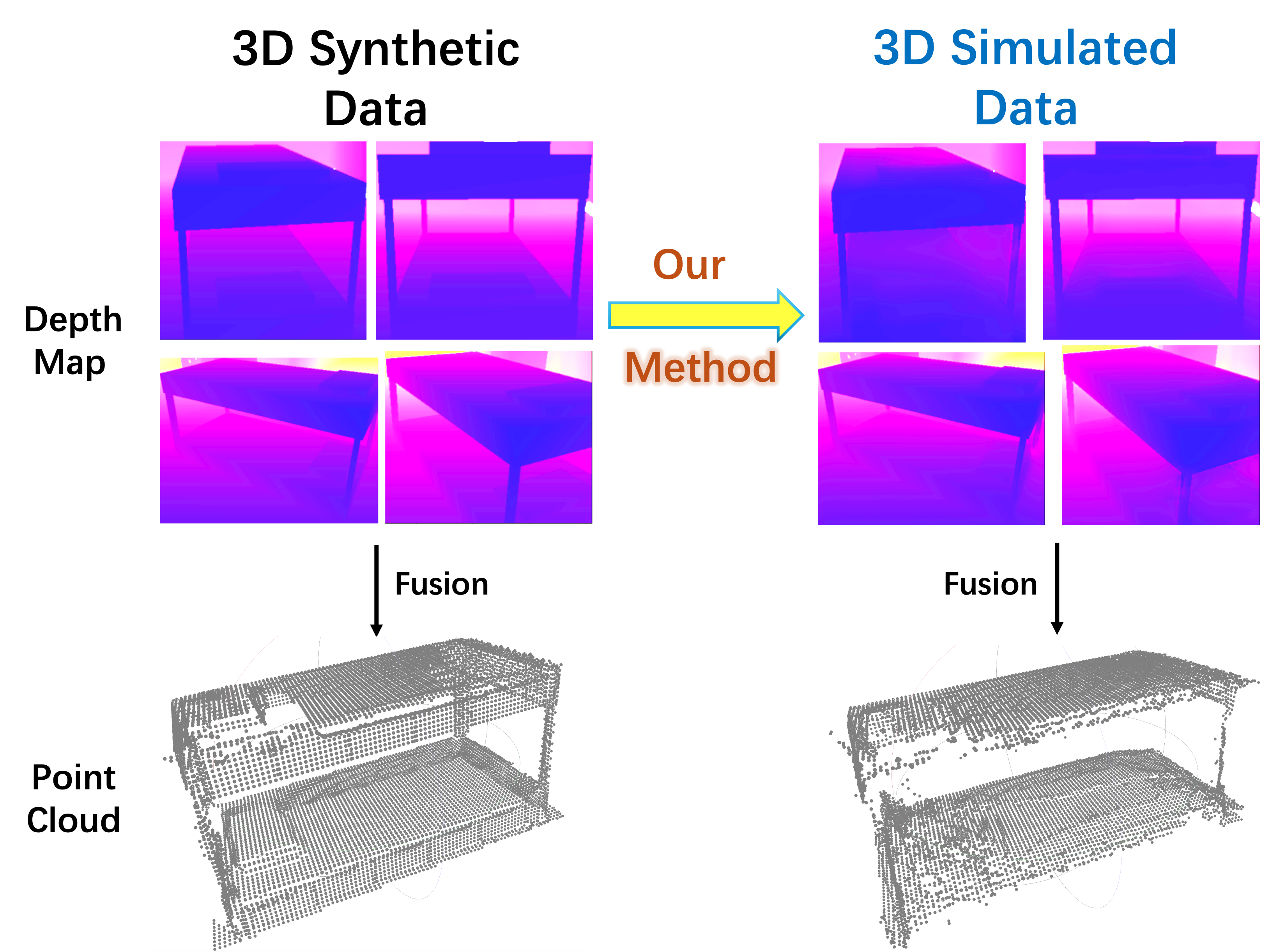
- [06/2025] One paper (Stable-Sim2Real) is accepted to ICCV2025 as Highlight (2.4%)! Paper and code are available.
- [05/2025] I was recognized as one of the CVPR2025 Outstanding Reviewers (5.6%)!
- [03/2025] One paper (TASTE-Rob) is accepted to CVPR2025. Paper and data are available.
- [11/2024] One paper (SAMPro3D) is accepted to 3DV2025. Paper and code are available.
- [08/2024] One paper (survey) is accepted to TPAMI. Paper is available.
- [07/2024] One paper (Free-ATM) is accepted to ECCV2024. Paper is available.
- [07/2024] MVImgNet is awarded WAIC Youth Outstanding Paper Nomination, 2024 (2024世界人工智能大会青年优秀论文提名奖)!
- [03/2024] One paper (RichDreamer) is accepted to CVPR2024 as Highlight (2.8%)! Paper and code are available.
- [11/2023] I was recognized as one of the NeurIPS2023 Top Reviewers (9.9%)!
- [08/2023] MVImgNet is awared CCF Outstanding Graphics Open-Source Dataset, 2023 (CCF-2023年度优秀图形开源数据集奖)!
- [05/2023] I was named one of the CVPR2023 Outstanding Reviewers (3.3%)!
- [03/2023] Three papers (MVImgNet, MM-3DScene, REC-MV) are accepted to CVPR2023. Papers, dataset, and codes are all available.
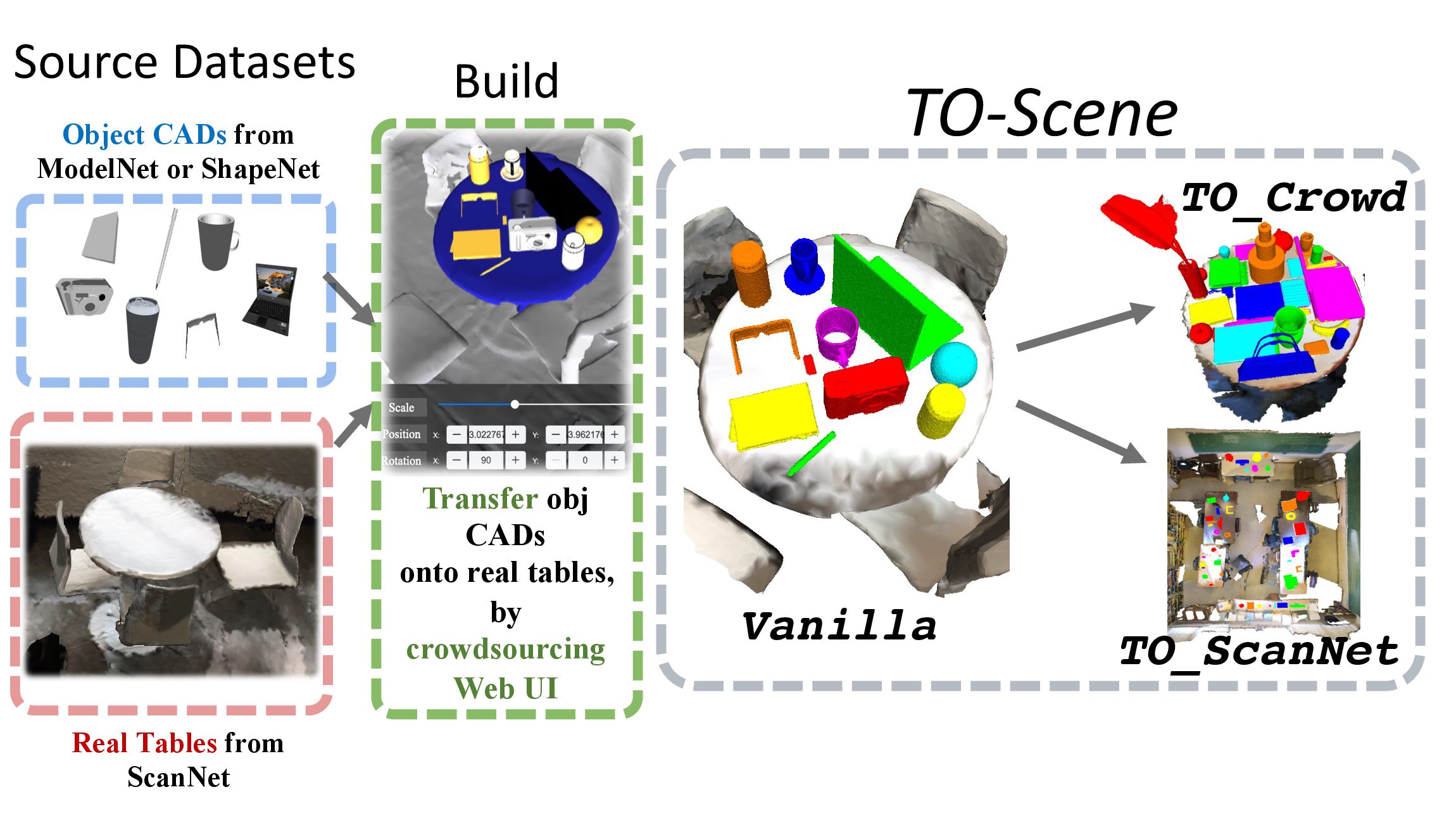
- [07/2022] One paper (TO-Scene) is accepted to ECCV2022 for Oral Presentation (2.7%)! Paper and dataset are available.
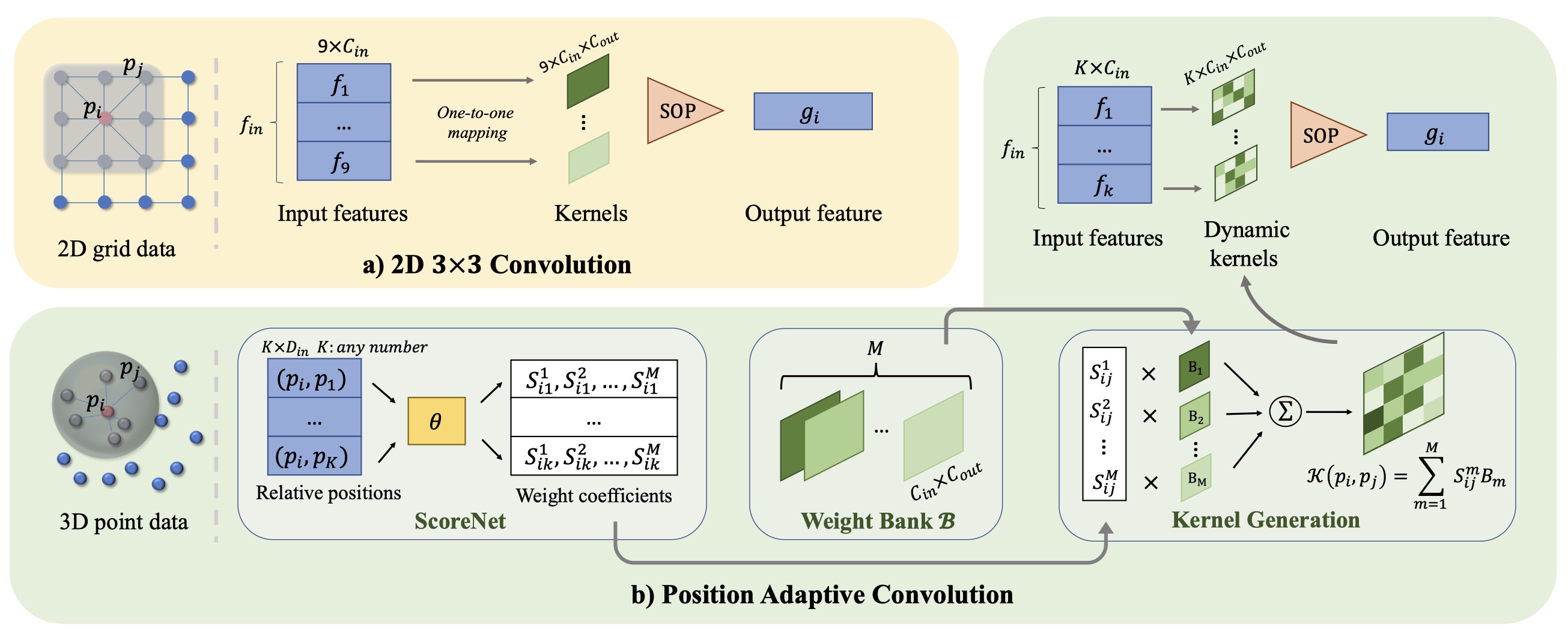
- [03/2021] One paper (PAConv) is accepted to CVPR2021. Paper and code are available.
- [12/2020] One paper (GDANet) is accepted to AAAI2021. Paper and code are available.
Publications
(* indicates equal contribution, † denotes project lead, ‡ means corresponding author)
Selected Representatives

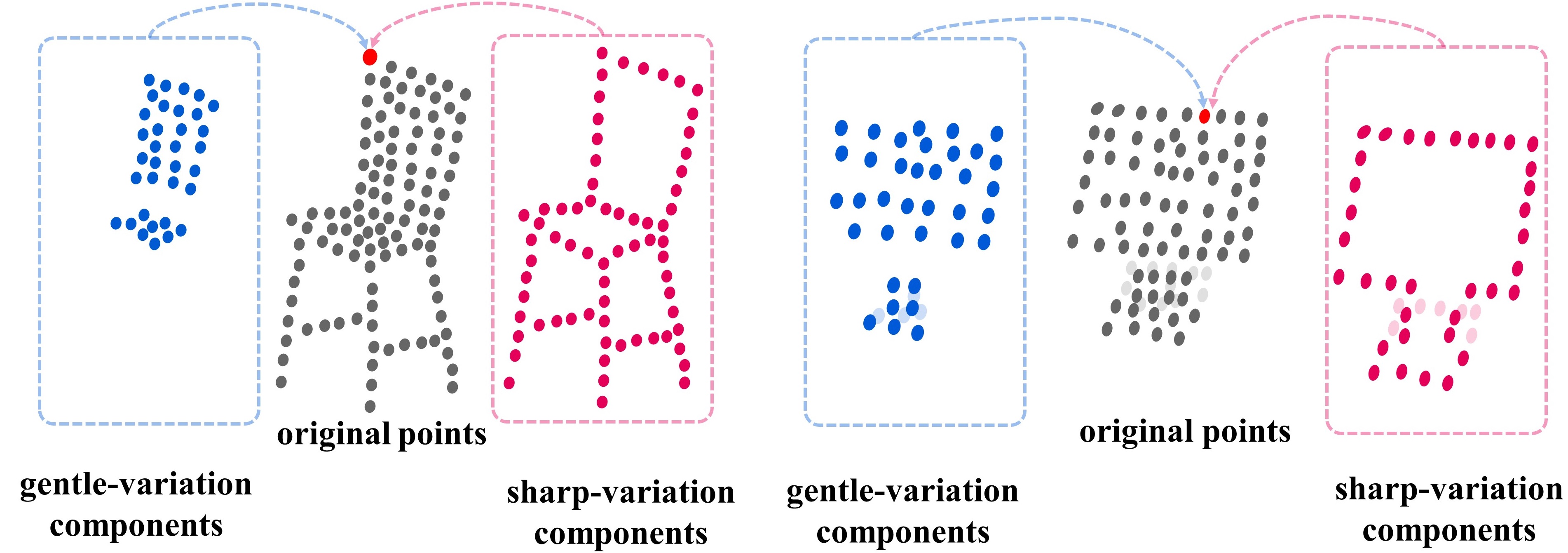
Learning Geometry-Disentangled Representation for Complementary Understanding of 3D Object Point Cloud
Mutian Xu*, David Junhao Zhang*, Zhipeng Zhou, Mingye Xu, Xiaojuan Qi, Yu Qiao‡.
(AAAI, 2021, BEST performance on OmniObject 3D robust perception) [paper][code]
Others

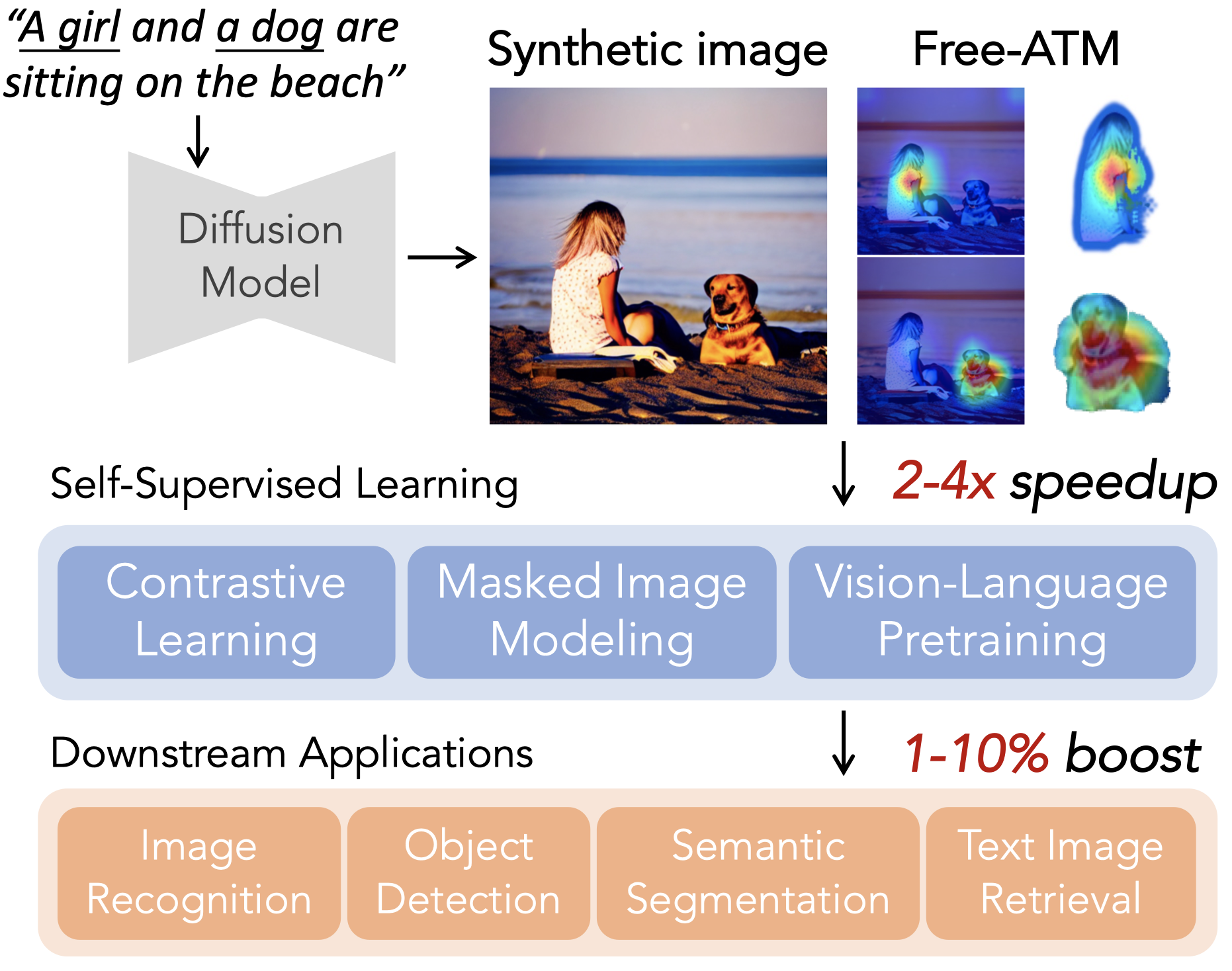
Free-ATM: Harnessing Free Attention Masks for Representation Learning on Diffusion-Generated Images
David Junhao Zhang, Mutian Xu†, Jay Zhangjie Wu, Chuhui Xue, Wenqing Zhang, Xiaoguang Han, Song Bai, Mike Zheng Shou‡. (†project lead)
(ECCV, 2024) [paper]


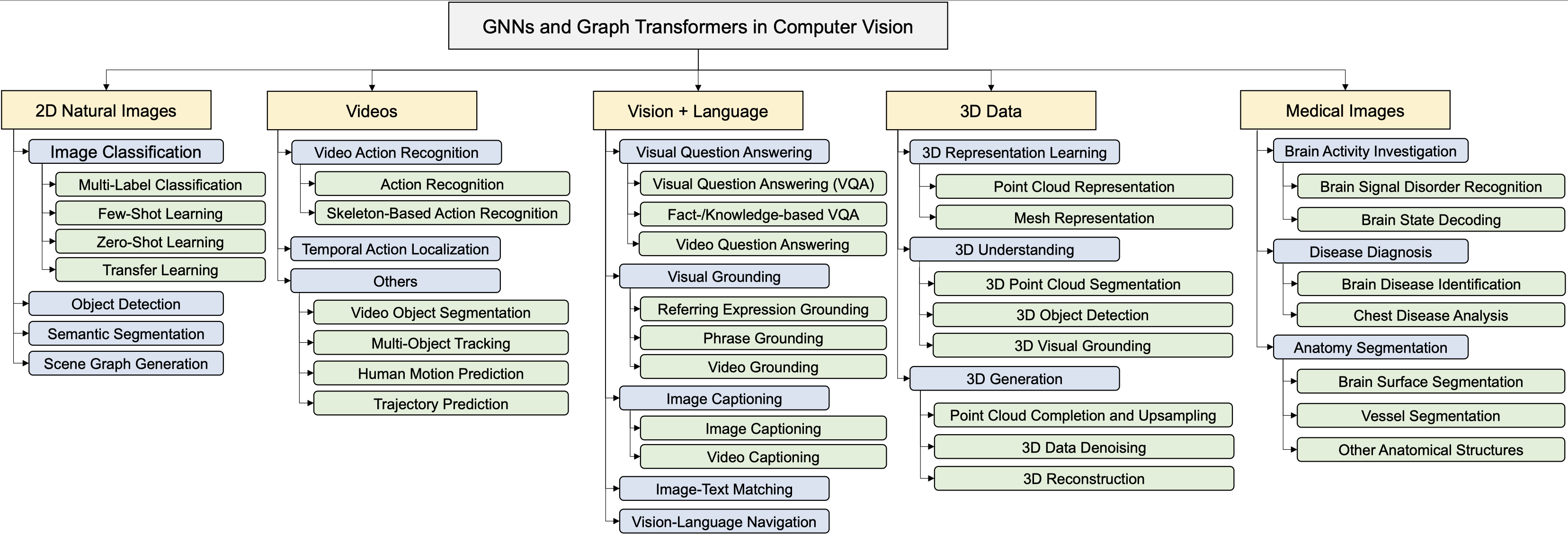
A Survey on Graph Neural Networks and Graph Transformers in Computer Vision: A Task-Oriented Perspective
Chaoqi Chen*, Yushuang Wu*, Qiyuan Dai*, Hong-Yu Zhou*, Mutian Xu, Sibei Yang‡, Xiaoguang Han‡, Yizhou Yu‡.
(TPAMI, 2024) [paper]
Activites & Certificates
| Presidential Award for Outstanding Doctoral Students of CUHKSZ |
| Outstanding Reviewer, ICCV 2025 (2.7%) |
| Outstanding Reviewer, CVPR 2025 (5.6%) |
| WAIC Youth Outstanding Paper Nomination Award (世界人工智能大会青年优秀论文提名奖, MVImgNet), 2024 |
| Top Reviewer, NeurIPS 2023 (9.9%) |
| Outstanding Reviewer, CVPR 2023 (3.3%) |
| CCF Outstanding Graphics Open-Source Dataset (CCF年度优秀图形开源数据集奖, MVImgNet), 2023 |
| Outstanding Teaching Assistant Award of CUHKSZ, 2022/24 |
| Journal Reviewer: TIP, IJCV, TVCG, NEUCOM, TMM, TMC, MVAP |
| Conference Reviewer: CVPR, ICCV, ECCV, SIGGRAPH Asia, ICLR, ICML, NeurIPS, IJCAI, WACV, ACCV |
Experience
-
06. 2020 – 02. 2021
Research Assistant
Topic: 3D Point Cloud Convolution
Advisor: Prof. Xiaojuan Qi
-
07. 2019 – 11. 2019
Visiting Student
Topic: 3D Object Point Cloud Classification and Segmentation
Advisor: Prof. Yu Qiao & Dr. Zhipeng Zhou
Talks
| "我要这paper有何用 ? ( Why Do I Need Papers ? )", Valse Webinar 2024 |
| Outstanding Student Forum of Valse 2023 |
| Outstanding Student Forum of China 3DV 2023 |
| Youth PhD Talk - ECCV 2022, invited by AI-TIME |
Teaching
| CUHKSZ-CSC1001: Introduction to Computer Science: Programming Methodology (Leading TA) |
| CUHKSZ-CSC1002: Computational Laboratory |
| CUHKSZ-CSC3002: Introduction to Computer Science: Programming Paradigms |
Miscellaneous
| 3rd place of the 31st School Singer Contest, Xidian University |
| Piano Professional Certificate Level 10 |
